Web Scraper - Pre-Scrape Clicks

Pre-Scrape clicks enable you to configure the page clicks that must be performed before starting the scraping. This document lists the typical use cases addressable through pre-scrape clicks.
Capture list data behind a button click
To extract data from certain websites, you may encounter information hidden behind buttons or links for each list element. One effective way to scrape such data is by utilizing the "Advanced -> Pre-Scrape Clicks" feature in the configuration settings of your Web Scraper task.
For example, see the below image of a web page. It has a list of contractors, and we want to scrape the phone number for each listing. The phone number is shown after clicking the "VIEW PHONE" link.
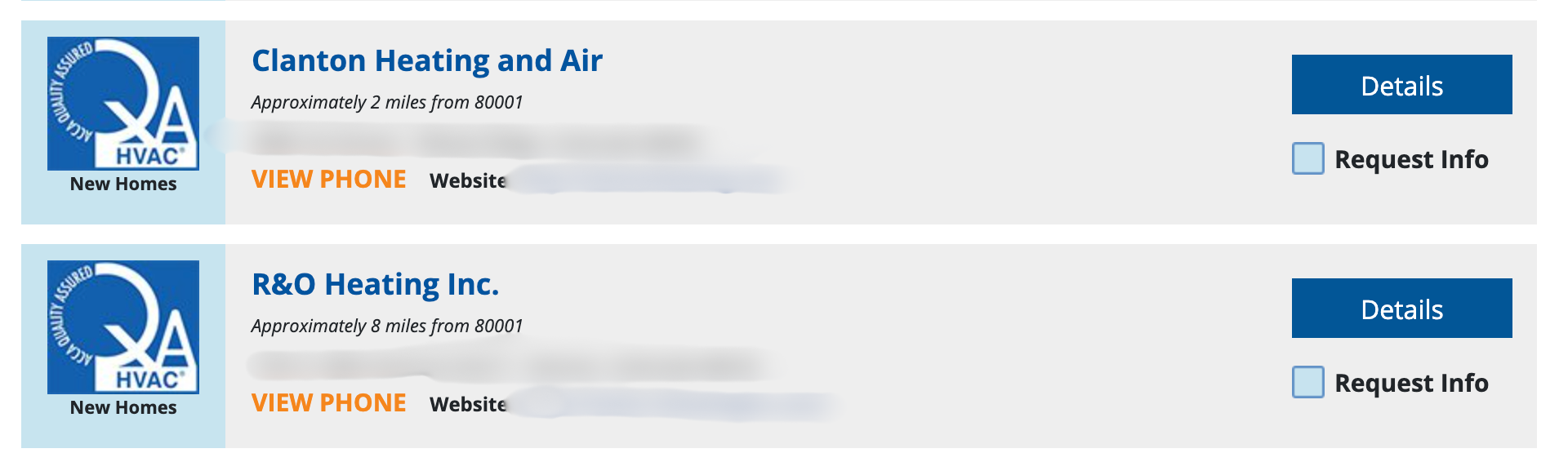
To achieve this, configure the "Pre-Scrape Clicks" option by selecting "Click once per list item" to ensure a click is triggered for each listing.
With this configuration, the following steps are executed by the scraper:
- Go to each listing.
- Click the specified button ("VIEW PHONE" in this case). Note: you can configure multiple "pre-scraper clicks".
- Then, scrape the configured fields for the list element.
Configure XPath for list-based pre-scrape clicks
You can use Byteline's Chrome extension to easily configure the XPath. It's important to note that the configuration steps differ based on whether you need to click elements for each list item or perform a single click on a web page.
XPath for "Click once per list item"
The following steps can be used to configure the XPath.
- Open the website in the Chrome browser.
- Install and click on Byteline's Chrome extension. Now enable it using the toggle button.

- Click on the "Capture List Elements" and then take your mouse cursor over the repeating elements. Once all the elements are yellow, perform a single click. The list of elements will turn green.
- Now, take the cursor to the "button" to click; the "VIEW PHONE" button in this example.
- Select "Link" and then click "COPY". Note: if "link" is not selectable, select the "Text" radio button.
- Go to the Byteline web scraper, select the "pre-scrape clicks" text box, and paste the data.

Capture page data after button clicks
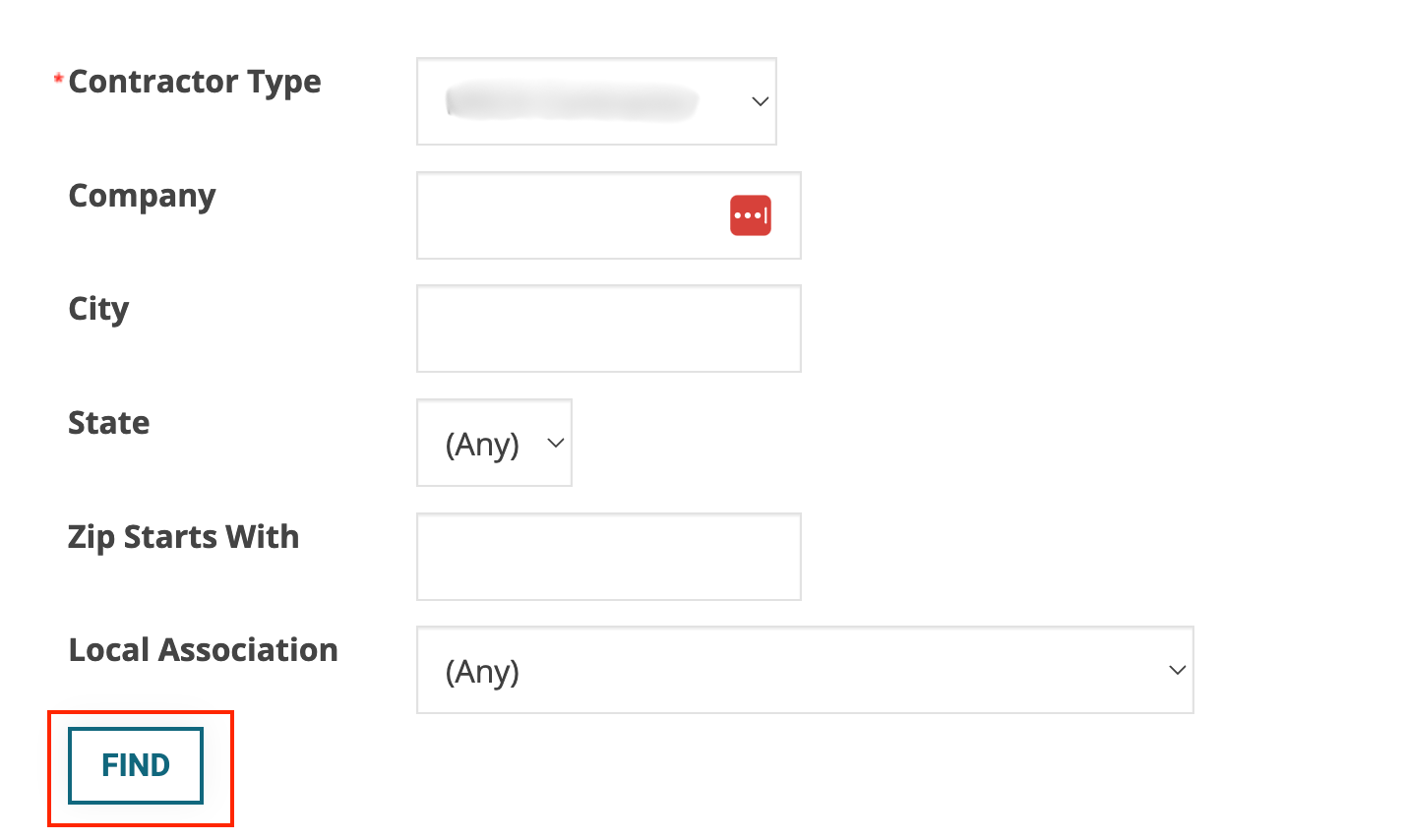
For this use case, we'll demonstrate how to scrape data that becomes visible post-button clicks. The starting web page content shows the below form. We want to use the default form values and click on the "Find" button.
Following this button click, the below results are shown. Subsequently, we will click on the "Show all 1201" link to reveal all results. Once all results are available, we can use our usual scraping config to scrape all the data.
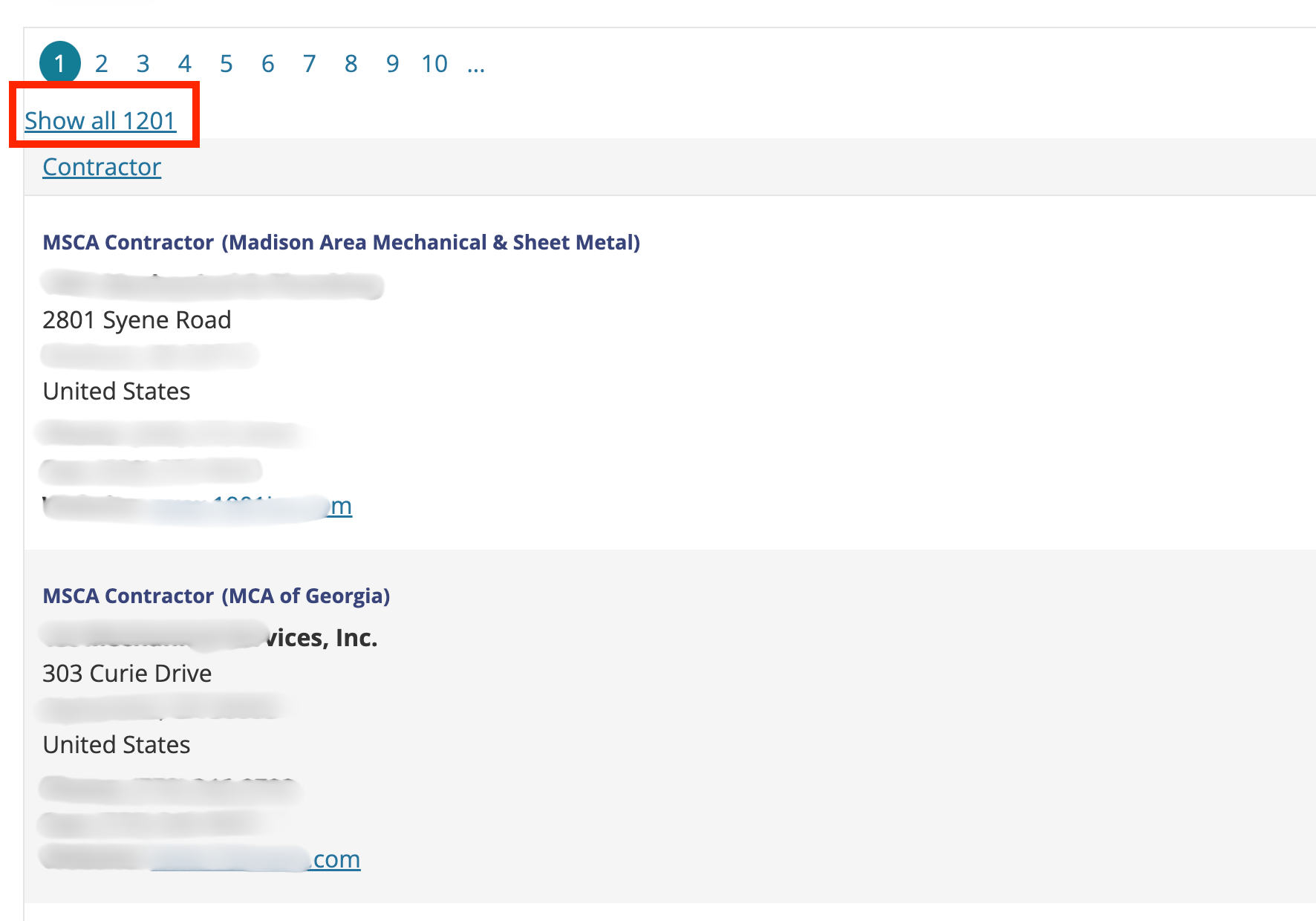
To summarize, we will use pre-scrape clicks to do the following:
- Click on the Find button.
- Click on the "Show all 1201" link.
Two pre-scraper clicks will be configured for the above steps.
Configure XPath for page-level pre-scrape clicks
We will use Byteline's Chrome extension to configure the XPath.

XPath for "Click once"
"Click once" is used when you want to click only once on a webpage. The following steps can be used to configure the XPath.
- Open the website in the Chrome browser.
- Install and click on Byteline's Chrome extension. Now enable it using the toggle button.
- Click on the "Capture Single Element" and then take your mouse cursor over the button or link to click. Once it turns yellow, perform a single click.
- Select "Link" and then click "COPY". Note: if "link" is not selectable, select the "Text" radio button.
- Go to the Byteline web scraper, select the "pre-scrape clicks" text box, and paste the data.

After using the steps in the above section, we will configure the two pre-scrape clicks at the page level. Our Web scraper advanced configuration should look like the following. The pre-scraper clicks are executed in the defined order.
